Instabilidade Google Cloud Expõe Riscos Críticos da Dependência de Provedor Único
Akamai Technologies
A instabilidade que atingiu a Google Cloud na última quinta-feira (13 de junho) serviu como um alerta vermelho para empresas e usuários em todo o mundo sobre os perigos críticos de depender exclusivamente de um único provedor de serviços em nuvem. O incidente, que afetou serviços essenciais como Gmail, Google Drive, Google Agenda e outras plataformas fundamentais para milhões de usuários, não foi um evento isolado, mas sim um lembrete contundente de que até mesmo os gigantes tecnológicos mais confiáveis estão sujeitos a falhas que podem paralisar operações globais em questão de minutos.
Durante o período de instabilidade, empresas ao redor do mundo experimentaram interrupções significativas em suas operações diárias, desde pequenos negócios que dependem do Gmail para comunicação até corporações multinacionais que utilizam a infraestrutura completa do Google Workspace para suas atividades críticas. A situação se tornou ainda mais preocupante quando outras plataformas importantes como Cloudflare, Spotify e até mesmo a Amazon Web Services (AWS) também registraram oscilações simultâneas, criando um efeito dominó que demonstrou a interconectividade vulnerável da infraestrutura digital moderna. Esta análise abrangente examina não apenas o que aconteceu durante o incidente, mas também as implicações de longo prazo para estratégias de continuidade de negócios e as lições cruciais que organizações de todos os tamanhos podem extrair desta experiência para fortalecer sua resiliência digital.
Anatomia da Falha: Como a Instabilidade se Manifestou Globalmente
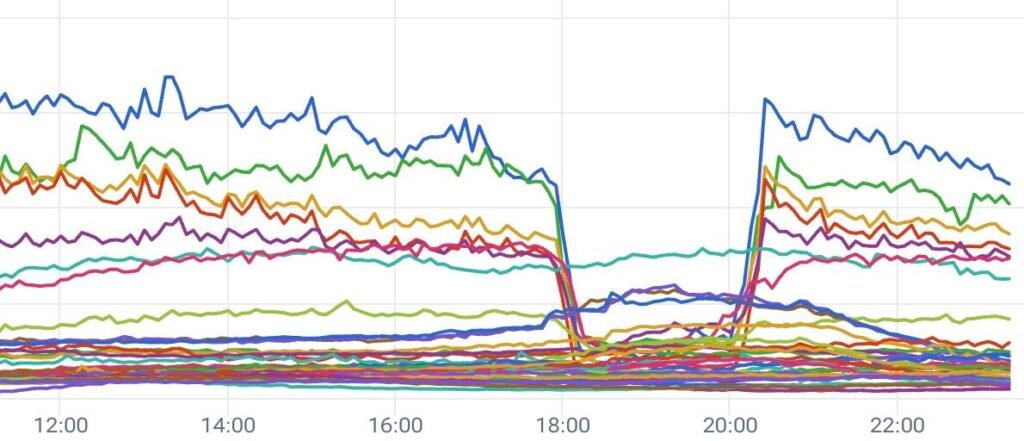
A instabilidade na Google Cloud não se manifestou de forma uniforme ao redor do globo, revelando padrões complexos que demonstram tanto a sofisticação quanto as vulnerabilidades dos sistemas de distribuição de tráfego modernos. Segundo análises detalhadas conduzidas pela Akamai Technologies, empresa reconhecida mundialmente por sua expertise em segurança cibernética e infraestrutura de nuvem, o comportamento do tráfego durante o incidente apresentou variações significativas entre diferentes regiões geográficas.
Cidades americanas como Los Angeles, Chicago, Seattle, San Jose e Dallas experimentaram quedas dramáticas no volume de tráfego, indicando que os serviços da Google Cloud nessas regiões foram severamente impactados ou completamente interrompidos. Essa concentração de problemas nas principais metrópoles americanas sugere que o epicentro da falha pode ter se originado em data centers críticos localizados nos Estados Unidos, onde a Google mantém algumas de suas infraestruturas mais importantes.
Paradoxalmente, enquanto as cidades americanas enfrentavam interrupções significativas, centros europeus como Frankfurt e Amsterdam registraram aumentos substanciais no volume de tráfego. Este fenômeno não foi coincidencial, mas sim resultado de mecanismos automáticos de failover que redirecionaram o tráfego afetado para regiões com infraestrutura funcionando normalmente. O failover, um processo técnico essencial para manutenção de serviços durante falhas, demonstrou funcionar parcialmente, mas também revelou limitações na capacidade de absorção de tráfego adicional por parte dos data centers europeus.
A disparidade regional observada durante o incidente ilustra a complexidade inerente aos sistemas de nuvem distribuída e como falhas localizadas podem ter repercussões globais imprevisíveis. Para empresas que operam internacionalmente, este padrão de falha destacou a importância crítica de compreender como seus dados e serviços são distribuídos geograficamente e quais mecanismos de proteção estão em vigor para diferentes regiões operacionais.
O Efeito Dominó: Quando Uma Falha Afeta Múltiplas Plataformas
O que tornou este incidente particularmente alarmante foi sua capacidade de afetar não apenas os serviços diretos da Google Cloud, mas também uma variedade de plataformas aparentemente independentes. Cloudflare, uma das principais redes de distribuição de conteúdo do mundo, Spotify, a plataforma de streaming musical líder global, e até mesmo a Amazon Web Services (AWS), principal concorrente da Google no mercado de nuvem, registraram oscilações durante o mesmo período.
Este efeito cascata revela a interconectividade profunda e muitas vezes invisível da infraestrutura digital moderna. Muitas empresas que acreditam ter diversificado seus fornecedores de tecnologia descobrem, durante crises como esta, que suas soluções “independentes” na verdade compartilham dependências fundamentais comuns. Por exemplo, um serviço pode usar AWS para hospedagem principal, mas depender de APIs do Google para funcionalidades específicas, ou utilizar Cloudflare para distribuição de conteúdo que, por sua vez, pode ter dependências de serviços do Google para certas operações.
A simultaneidade das falhas também levanta questões importantes sobre a concentração de infraestrutura digital crítica nas mãos de poucos fornecedores globais. Quando gigantes como Google, Amazon e Cloudflare experimentam problemas no mesmo período, isso demonstra vulnerabilidades sistêmicas que vão além de falhas técnicas isoladas. Pode indicar problemas em infraestruturas compartilhadas subjacentes, como cabos submarinos de internet, sistemas de DNS de alto nível, ou até mesmo questões em fornecedores de energia que atendem múltiplos data centers.
Para empresas que dependem de múltiplas plataformas digitais para suas operações, o incidente serviu como um teste de estresse não programado, revelando pontos únicos de falha que muitas organizações não sabiam que existiam. Empresas que implementaram estratégias de redundância descobriram que suas soluções de backup também foram afetadas, destacando a necessidade de auditorias mais profundas das dependências tecnológicas e planos de contingência mais robustos.
Análise Técnica: Mecanismos de Failover e Redistribuição de Tráfego
Os dados coletados pela Akamai durante o período de instabilidade oferecem insights técnicos valiosos sobre como os sistemas modernos de nuvem respondem a falhas em larga escala. O mecanismo de failover observado durante o incidente representa tanto um sucesso parcial dos sistemas de proteção quanto uma demonstração de suas limitações práticas.
O failover automático funciona detectando quando serviços em uma região específica tornam-se indisponíveis ou apresentam degradação significativa de performance, redirecionando automaticamente as solicitações para data centers alternativos que mantêm funcionamento normal. No caso específico desta instabilidade, o sistema conseguiu identificar problemas nas regiões americanas afetadas e redirecionar uma porção significativa do tráfego para infraestruturas europeias.
No entanto, este redirecionamento revelou gargalos importantes na capacidade de absorção dos data centers de destino. O aumento súbito de tráfego em Frankfurt e Amsterdam, embora tenha mantido muitos serviços funcionando, também criou latência adicional e possível degradação de performance para usuários que normalmente seriam atendidos por infraestruturas geograficamente mais próximas. Usuários americanos acessando serviços através de data centers europeus experimentaram tempos de resposta significativamente maiores, demonstrando que failover, embora essencial, não é uma solução transparente.
A análise também revelou que nem todos os serviços foram igualmente beneficiados pelos mecanismos de failover. Serviços que requerem sincronização de dados em tempo real ou que dependem de recursos computacionais específicos localizados em regiões afetadas enfrentaram maiores dificuldades para migração automática. Esta diferenciação na capacidade de recuperação entre diferentes tipos de serviços destaca a importância de compreender as características técnicas específicas de cada aplicação ao planejar estratégias de continuidade.
Os gráficos de tráfego coletados durante o incidente também mostraram padrões interessantes de recuperação gradual, com some serviços retornando à normalidade mais rapidamente que outros, sugerindo que a Google implementou uma estratégia de restauração priorizada, focando primeiro em serviços considerados mais críticos antes de restaurar completamente toda a infraestrutura afetada.
Impacto Empresarial: Custos Ocultos da Dependência Única
O impacto financeiro e operacional da instabilidade na Google Cloud estendeu-se muito além das poucas horas de interrupção direta dos serviços. Para empresas que construíram suas operações inteiramente ao redor do ecossistema Google, o incidente representou uma paralisia temporária que resultou em perdas mensuráveis e implicações de longo prazo para a confiança dos clientes.
Pequenas e médias empresas que dependem exclusivamente do Google Workspace para comunicação, armazenamento de documentos e colaboração enfrentaram interrupções significativas em suas operações diárias. Equipes de vendas perderam acesso a propostas críticas armazenadas no Google Drive durante apresentações importantes, departamentos de marketing não conseguiram acessar campanhas publicitárias em andamento, e equipes de suporte ao cliente ficaram impossibilitadas de responder adequadamente devido à indisponibilidade do Gmail empresarial.
Para organizações maiores, o impacto foi multiplicado pela escala de suas operações. Empresas multinacionais que utilizam Google Cloud para hospedagem de aplicações críticas enfrentaram não apenas interrupções internas, mas também impactos diretos em seus clientes externos. E-commerces hospedados na plataforma perderam vendas durante períodos de pico, aplicativos móveis perderam funcionalidades essenciais, e plataformas de streaming enfrentaram interrupções no fornecimento de conteúdo.
O custo oculto mais significativo, no entanto, pode ser a erosão da confiança dos clientes. Empresas que prometem disponibilidade de 99.9% para seus próprios clientes descobriram que dependem de fornecedores que, ocasionalmente, não conseguem cumprir essas mesmas promessas. Esta realização forçou muitas organizações a reavaliar seus acordos de nível de serviço (SLAs) e considerar como comunicar efetivamente com clientes durante interrupções que estão além de seu controle direto.
Além dos impactos imediatos, o incidente também destacou custos de oportunidade relacionados à falta de estratégias de redundância. Empresas com arquiteturas multi-cloud conseguiram migrar operações críticas para provedores alternativos, mantendo continuidade operacional, enquanto organizações dependentes de um único fornecedor foram forçadas a esperar passivamente pela resolução dos problemas.
Perspectiva Global: Lições de Outros Incidentes Históricos
A instabilidade na Google Cloud não é um fenômeno isolado, mas parte de um padrão crescente de incidentes de alta visibilidade que têm afetado os principais provedores de nuvem ao longo dos últimos anos. Uma análise histórica de eventos similares oferece perspectivas valiosas sobre tendências emergentes e a evolução das vulnerabilidades em infraestruturas digitais críticas.
Em 2021, a Amazon Web Services enfrentou uma interrupção significativa que afetou milhares de sites e serviços, incluindo Netflix, Spotify, e até mesmo serviços governamentais. O incidente durou várias horas e demonstrou como a concentração de serviços em um único provedor pode criar pontos únicos de falha com impacto sistêmico. Similarmente, o Facebook (agora Meta) experimentou uma das interrupções mais longas de sua história em outubro de 2021, quando problemas de configuração de DNS tornaram inacessíveis não apenas o Facebook, mas também Instagram, WhatsApp e outras propriedades da empresa.
Microsoft Azure também não está imune a estes desafios, tendo enfrentado múltiplas interrupções significativas que afetaram serviços do Office 365, Teams, e outras ferramentas empresariais críticas. Cada um destes incidentes compartilha características comuns: propagação rápida através de múltiplos serviços, impacto desproporcional em empresas dependentes de um único ecossistema, e recuperação que requer coordenação complexa entre diferentes componentes de infraestrutura.
Internacionalmente, diferentes regiões têm experimentado vulnerabilidades específicas relacionadas à concentração de infraestrutura digital. Na Europa, regulamentações como GDPR criaram requisitos adicionais de localização de dados que, paradoxalmente, podem aumentar riscos de dependência regional. Na Ásia, a rápida digitalização de economias emergentes criou dependências críticas de infraestruturas que ainda estão sendo desenvolvidas e testadas em escala.
O padrão emergente destes incidentes globais sugere que, à medida que nossa dependência de serviços digitais aumenta, a magnitude potencial de interrupções também cresce exponencialmente. Cada incidente serve como um teste de estresse para a resiliência digital global, revelando novas vulnerabilidades e forçando a evolução de melhores práticas de continuidade de negócios.
Estratégias de Mitigação: Construindo Resiliência Através de Arquiteturas Multi-Cloud
A implementação efetiva de estratégias multi-cloud representa uma das defesas mais robustas contra os riscos demonstrados pela instabilidade na Google Cloud. No entanto, a transição de uma arquitetura de fornecedor único para uma abordagem distribuída requer planejamento cuidadoso, investimento significativo e compreensão profunda das complexidades técnicas envolvidas.
Uma arquitetura multi-cloud verdadeiramente efetiva vai além de simplesmente contratar múltiplos fornecedores; requer o desenvolvimento de uma estratégia integrada que considere como diferentes serviços interagem, como dados são sincronizados entre plataformas, e como aplicações podem ser migradas rapidamente entre ambientes durante emergências. Empresas que implementaram com sucesso estas estratégias normalmente começam identificando serviços críticos que requerem redundância imediata versus aplicações que podem tolerar interrupções temporárias.
A distribuição geográfica representa outro componente crucial de estratégias de resiliência efetivas. Empresas devem considerar não apenas quais provedores utilizar, mas também onde seus dados e aplicações estão fisicamente localizados. Uma estratégia verdadeiramente robusta distribui recursos críticos através de múltiplas regiões geográficas e múltiplos provedores, garantindo que eventos localizados não possam comprometer completamente as operações empresariais.
Tecnologias de containerização e orquestração, como Kubernetes, têm facilitado significativamente a implementação de estratégias multi-cloud, permitindo que aplicações sejam desenvolvidas de forma agnóstica a provedores específicos. Esta abordagem permite migração mais rápida entre ambientes e reduz dependências de serviços proprietários específicos que podem criar aprisionamento tecnológico.
No entanto, estratégias multi-cloud também introduzem complexidades adicionais, incluindo custos aumentados de gerenciamento, desafios de segurança relacionados a múltiplas interfaces, e necessidade de expertise técnica mais diversificada. Organizações devem equilibrar cuidadosamente os benefícios de resiliência aumentada contra os custos e complexidades adicionais introduzidos por arquiteturas distribuídas.
Análise de Impacto: Repercussões Econômicas e Estratégicas
O impacto econômico da instabilidade na Google Cloud estende-se muito além das perdas diretas experimentadas durante o período de interrupção, criando ondas de repercussão que afetam decisões estratégicas de longo prazo em organizações ao redor do mundo. Uma análise detalhada destes impactos revela como incidentes pontuais podem alterar fundamentalmente o panorama competitivo e as estratégias de investimento em tecnologia.
Para o setor de tecnologia como um todo, o incidente reforçou a importância crescente de empresas especializadas em resiliência e continuidade de negócios. Fornecedores de soluções de backup, empresas de consultoria em arquiteturas multi-cloud, e provedores de serviços de recuperação de desastres experimentaram aumento significativo na demanda por seus serviços nas semanas seguintes ao incidente. Este fenômeno demonstra como falhas em grandes provedores podem, paradoxalmente, criar oportunidades de mercado para fornecedores especializados em soluções de mitigação.
Do ponto de vista de investimentos empresariais, muitas organizações foram forçadas a reavaliar seus orçamentos de tecnologia, destinando recursos adicionais para estratégias de redundância que anteriormente eram consideradas desnecessárias ou excessivamente caras. CFOs e CIOs que previamente resistiam a investimentos em arquiteturas multi-cloud devido aos custos adicionais descobriram que os custos de interrupção podem exceder significativamente os investimentos preventivos em resiliência.
O incidente também impactou as estratégias de pricing e contratos dos principais provedores de nuvem. Clientes empresariais começaram a negociar cláusulas de SLA mais rigorosas, penalidades por interrupção mais severas, e garantias adicionais de disponibilidade. Esta pressão competitiva forçou provedores a reavaliar suas estruturas de pricing e investir mais pesadamente em infraestruturas de redundância.
Para economias nacionais, especialmente aquelas com setores digitais em rápido crescimento, o incidente destacou vulnerabilidades estratégicas relacionadas à dependência de infraestruturas controladas por empresas estrangeiras. Governos ao redor do mundo intensificaram discussões sobre soberania digital e a necessidade de desenvolver capacidades nacionais de nuvem como questões de segurança nacional.
Perspectiva Comparativa: Modelos de Resiliência ao Redor do Mundo
Diferentes regiões geográficas e setores industriais têm desenvolvido abordagens distintas para gerenciar riscos de dependência de provedores únicos, oferecendo modelos comparativos valiosos para organizações que buscam implementar estratégias de resiliência mais efetivas. Uma análise dessas diferentes abordagens revela tanto sucessos quanto limitações de diversas estratégias de mitigação.
Na União Europeia, iniciativas como o projeto GAIA-X representam tentativas ambiciosas de criar alternativas regionais aos dominantes provedores americanos de nuvem. Esta abordagem prioriza soberania digital e conformidade regulatória, mas ainda enfrenta desafios significativos relacionados à escala e competitividade tecnológica. Empresas europeias que adotaram estratégias híbridas, combinando provedores locais com soluções globais, frequentemente relatam maior complexidade operacional, mas também maior controle sobre conformidade regulatória.
No setor financeiro, onde regulamentações rigorosas e requisitos de continuidade são fundamentais, muitas instituições desenvolveram arquiteturas tri-cloud ou quad-cloud, distribuindo operações críticas através de múltiplos provedores com capacidades de failover automatizado. Bancos líderes como JPMorgan Chase e Goldman Sachs investiram bilhões em infraestruturas proprietárias complementadas por múltiplos provedores de nuvem pública, criando níveis de redundância que, embora caros, provaram ser efetivos durante múltiplos incidentes de interrupção.
Empresas asiáticas, particularmente aquelas baseadas na China, frequentemente operam sob modelos híbridos que combinam provedores locais com soluções internacionais, criando estratégias de resiliência que consideram tanto limitações técnicas quanto restrições regulatórias. Gigantes tecnológicos como Alibaba e Tencent desenvolveram ecossistemas de nuvem robustos que servem tanto como alternativas quanto como complementos aos provedores ocidentais.
Start-ups e empresas menores frequentemente adotam abordagens mais pragmáticas, utilizando serviços de múltiplos provedores através de plataformas de abstração que simplificam o gerenciamento multi-cloud. Estas soluções, embora menos customizadas que implementações empresariais de grande escala, oferecem caminhos mais acessíveis para pequenas organizações implementarem estratégias básicas de redundância.
Perguntas Frequentes Sobre Dependência de Provedor Único e Estratégias Multi-Cloud
1. Como posso avaliar se minha empresa está muito dependente de um único provedor de nuvem?
A avaliação da dependência excessiva requer uma auditoria abrangente de todos os serviços digitais utilizados pela organização. Comece mapeando todos os serviços críticos para suas operações diárias: email, armazenamento de arquivos, aplicações de negócio, sistemas de backup, e plataformas de comunicação. Se mais de 70% destes serviços dependem de um único provedor, ou se a interrupção de um provedor paralisaria completamente suas operações por mais de algumas horas, sua organização provavelmente enfrenta riscos significativos de dependência excessiva.
2. Quais são os primeiros passos para implementar uma estratégia multi-cloud sem interromper operações existentes?
A implementação de estratégias multi-cloud deve ser gradual e priorizada. Comece identificando serviços não-críticos que podem ser migrados ou duplicados em provedores alternativos sem impacto operacional significativo. Implemente soluções de backup em provedores diferentes antes de migrar aplicações de produção. Desenvolva competências internas em múltiplas plataformas através de treinamento e projetos piloto. Estabeleça políticas claras sobre quais tipos de dados e aplicações devem ser distribuídos versus centralizados.
3. Os custos de uma arquitetura multi-cloud compensam os benefícios de resiliência?
Os custos de arquiteturas multi-cloud variam significativamente dependendo da implementação específica, mas geralmente representam aumentos de 20-40% nos custos de infraestrutura comparados a estratégias de provedor único. No entanto, uma análise de custo-benefício deve considerar não apenas custos diretos, mas também custos potenciais de interrupção, perda de produtividade, danos à reputação, e penalidades contratuais. Para a maioria das empresas que dependem criticamente de infraestrutura digital, os custos de interrupção frequentemente excedem significativamente os investimentos preventivos em redundância.
4. Como garantir que estratégias multi-cloud não criem vulnerabilidades de segurança adicionais?
Implementações multi-cloud requerem estratégias de segurança mais sofisticadas, incluindo gerenciamento unificado de identidade e acesso, monitoramento de segurança centralizado, e políticas consistentes de proteção de dados através de múltiplas plataformas. Utilize soluções de segurança agnósticas a provedores, implemente criptografia de dados em trânsito e em repouso, e mantenha auditoria contínua de configurações de segurança. Considere trabalhar com consultores especializados em segurança multi-cloud para identificar e mitigar vulnerabilidades específicas de arquiteturas distribuídas.
5. Pequenas empresas podem implementar estratégias multi-cloud efetivas com recursos limitados?
Pequenas empresas podem implementar versões simplificadas de estratégias multi-cloud utilizando serviços gerenciados e plataformas de abstração que reduzem complexidade técnica. Comece com estratégias básicas como utilizar provedores diferentes para email e armazenamento de arquivos, implementar backups automatizados em múltiplas plataformas, e utilizar serviços de DNS e CDN que oferecem failover automático. Muitas soluções SaaS modernas oferecem integrações multi-cloud nativas que permitem pequenas empresas obterem benefícios de redundância sem necessidade de expertise técnica avançada.
Conclusão: Transformando Crises em Oportunidades de Fortalecimento Digital
A instabilidade que afetou a Google Cloud em 13 de junho de 2025 deve ser vista não apenas como um incidente técnico isolado, mas como um catalisador fundamental para a evolução das estratégias de resiliência digital empresarial. Este evento demonstrou de forma inequívoca que mesmo os provedores de tecnologia mais confiáveis e tecnicamente avançados estão sujeitos a falhas que podem ter repercussões globais significativas, forçando organizações de todos os tamanhos a reavaliar suas abordagens para continuidade de negócios e gerenciamento de riscos tecnológicos.
As lições extraídas deste incidente transcendem questões puramente técnicas, revelando a necessidade de uma mudança fundamental na forma como empresas concedem e gerenciam dependências tecnológicas críticas. A era da dependência confortável de fornecedores únicos, por mais confiáveis que pareçam, está chegando ao fim, sendo substituída por uma nova realidade onde resiliência, redundância e flexibilidade devem ser priorizadas desde o estágio inicial de planejamento tecnológico.
O futuro pertence às organizações que conseguirem equilibrar efetivamente os benefícios de ecossistemas integrados com a segurança de arquiteturas distribuídas e resilientes. Empresas que tratarem este incidente como um alarme para ação, investindo proativamente em estratégias multi-cloud, diversificação de fornecedores, e planos robustos de continuidade de negócios, estarão melhor posicionadas não apenas para sobreviver a futuras interrupções, mas para transformar estes desafios em vantagens competitivas sustentáveis.
A jornada em direção à resiliência digital verdadeira requer investimento, planejamento cuidadoso, e mudanças culturais organizacionais significativas, mas os custos desta transformação são insignificantes comparados aos riscos de permanecer vulnerável em um mundo digital cada vez mais interconectado e interdependente.
Avalie hoje mesmo a dependência tecnológica de sua empresa e desenvolva uma estratégia de resiliência digital antes que a próxima interrupção afete suas operações críticas.












Publicar comentário
Você precisa fazer o login para publicar um comentário.